- 软件



/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/
 腾讯QQ下载v9.7.5.28965 最新版
腾讯QQ下载v9.7.5.28965 最新版 QQ游戏大厅2023官方下载正式版v5.47.57938.0 最新版
QQ游戏大厅2023官方下载正式版v5.47.57938.0 最新版 QQ电脑管家v15.0.22206.230 最新正式版
QQ电脑管家v15.0.22206.230 最新正式版 雷神模拟器精简工具v1.0 绿色版
雷神模拟器精简工具v1.0 绿色版 bilibili哔哩哔哩电脑版官方下载v1.9.2.2092 桌面客户端
bilibili哔哩哔哩电脑版官方下载v1.9.2.2092 桌面客户端 鲁大师官方下载v6.1023.3545.313 官方最新版
鲁大师官方下载v6.1023.3545.313 官方最新版 同花顺炒股软件电脑版v9.20.12 最新版
同花顺炒股软件电脑版v9.20.12 最新版 迅雷11正式版客户端v11.4.3.2054 官方版
迅雷11正式版客户端v11.4.3.2054 官方版 优酷视频2023版pc客户端v9.2.15.1002 官方最新版
优酷视频2023版pc客户端v9.2.15.1002 官方最新版 驱动人生8最新版v8.16.17.50 官方版
驱动人生8最新版v8.16.17.50 官方版水淼万能文章采集器这个软件官方报价400元,有网友分享了破解版本,下边在这里分享给需要的用户使用!
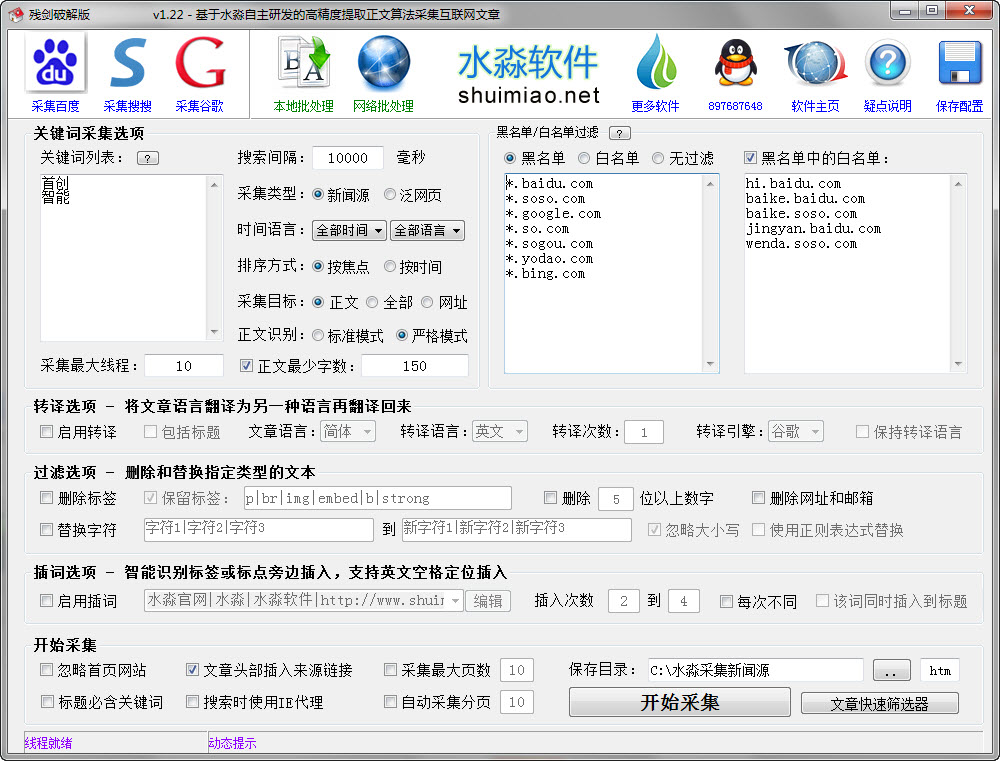
水淼软件出品的一款基于高精度正文识别算法的互联网文章采集器。支持按关键词采集百度等搜索引擎的新闻源(news.baidu.com)和泛网页(www.baidu.com),支持采集指定网站栏目下的全部文章。 更多介绍..
水淼软件独家首创智能的万能算法,可以精确提取网页里的正文部分保存为文章。
支持去标签、链接、邮箱等格式化处理。还有插入关键词功能,可以识别标签或标点旁边插入,并且能识别英文空格间距插入。
更有文章转译功能,也就是可以将文章从一种语言如中文转到另一种语言如英文或日文,再从英文或日文转回中文,这样就是一个转译周期,可以设定转译周期循环多次(转译次数)。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司开发的信息采集系统,售价往往达到上万甚至更多,而水淼的这款软件也是一款信息采集系统,功能跟市面上昂贵售价的软件有相通之处,但价格只有区区几百元,性价比如何试试就知。
什么是高精度正文识别算法
此算法由水淼自主研发,可以在一个网页里提取出正文部分,通常精度可以达到95%,如果再进一步设置最少字数,采集的文章的精度(正确性)可以达到99%。同时文章标题也实现99%的提取精度。当然,一些网页排版格式比较混乱、不规则时,该精度可能有所下降。
正文提取模式
正文提取算法有3种模式,标准、严格、精确标签。大多数情况,标准和严格模式是相同的提取结果。下面说的是特殊情况:
标准模式:即一般性提取,大多数时候能够精确提取正文,但一些特殊页面会导致提取到一些不需要内容(但本模式能够较好识别类似百度经验的文章页面)
严格模式:顾名思义,比标准模式严格一点,可以很大程度避免不相关内容提取为正文,但对于特殊分段页面如百度经验的页面(不是一般<p></p><br>段落,而是有格式的多个独立div段),一般只能提取到某一段,而标准模式则可以提取全部段。
精确标签:当标准和严格模式不管用时,可以精确指定目标正文的标签头。本模式只适合网络批处理。
所以可以根据实际情况来切换模式。可以使用本地批处理的读网页正文功能来测试指定网页适合哪种模式提取。
采集时的处理选项
采集时可以同时进行转译、过滤、查词等处理。对于已采集好的文章可以使用《本地批处理》处理。
其中的转译功能,就是将中文翻译成英文再翻译回中文,也就产生了伪原创效果。支持原格式转译,也就是不改变文章原有标签结构、排版格式。
采集目标为网址
可以在网址模板里插入 #网址#、#标题#来组合引用
分页采集和相对路径转为绝对路径
打勾“自动采集分页”就能将分页文章采集合并,编辑框设置值为采集分页的最大数量。建议设置一个有限值如10页,避免一些分页过多的采集耗费时间长,合并后的文章体积大。如果需要采集全部分页,可以设置为0。
而文章里的所有相对路径都将自动转为绝对路径,如此可确保图片等正常显示。
多线程
支持多线程高速采集网页。可以根据网速而定,电信2m可以5个线程,电信4m可以10个线程,更多以此类推,但需适当设置,设置太多将可能严重影响采集效率甚至影响系统效率。如果采集时有其他占用流量的软件在运行比如在线视频播放,可以适当降低线程数。
文章标题和文章内容重复的处理
程序可以智能判断并过滤重复文章
当采集到的文章标题(文件名)与本地已经保存的文章标题相同时,水淼将首先判断两篇文章的相似度,当相似度大于 60% 时,水淼判断为相同文章,这时再比较两篇文章的文字多寡,自动使用文字多的文章覆盖写出到相同文件名处。这样的生成情况是不累加到生成数量的。
当相似度低于 60% 时,水淼判断为不同文章,将自动重命名标题(取3到5个随机字母接在标题尾)保存到文件。
文章快速筛选器
虽然水淼研究了一个准确率极高的正文提取算法,但难免还是有极少数提取错误,这些错误主要是:目标网页的主体是在线视频,或主体内容过于简短而无法形成正文的特征。因此可以通过设置提取最终结果的字数多少来提高准确率(在“正文最少字数”参数,这个字数是程序将正文去标签、去行、去空格之后的纯文字字数)。
而文章快速筛选器就是为了快速查看采集好的文章,方便判断删除提取正文错误的文章。同时也方便基于网络信息采集目的而需要进行的炼选过程。
生成篇数不固定的问题
百度、搜搜默认每页100条结果,谷歌默认每页10条结果。
一些网站访问速度超时(尤其是谷歌收录的不少都是一些被墙的网站),或设置了正文最少字数,或程序忽略已在本地有同名的相似内容文章,或黑名单白名单的过滤等,都会造成实际生成篇数低于一页搜索最大结果数。
总体来说,百度采集的质量最好,生成篇数贴近搜索结果数。
文字教程:采集指定网站的文章
首先说明一点(以百度举例),新闻源的主页是 news.baidu.com,泛网页的主页是 www.baidu.com,在这个主页里可以输入关键词搜索文章,而程序里给出关键词列表就是由程序来批量搜索网页,并抓取回搜索结果,然后提取结果里的网址,再对这个网址采集目标网页的正文和标题。
泛网页的关键词可以直接使用 site、inurl 等搜索引擎支持的语法,想要采集指定网站就必须选中泛网页单选框。
想要采集百度经验,直接输入关键词 site:jingyan.baidu.com ,即可自动采集百度经验上的文章
(在采集百度经验时,如果启用黑名单,需去掉 *.baidu.com 项,或在黑名单中的白名单里添加 jingyan.baidu.com 项;也可以直接选无过滤)。
另外,指定采集某网站时,请将线程数量设置为1或2个,否则过多线程同时对一个网站进行访问,第一可能会造成该网站的反应效率问题,反而采集更慢,同时也影响别人对该网站的访问体验,第二是如果该网站有监测功能发现你多个线程在对着他访问,可能会直接屏蔽掉你的访问。

文章采集软件可以采集不同网站、论坛和博客的内容到自己的博客程序中,可每天采集最新的文章内容,定时扫描对方网站是否有新文章,如有,软件会自动把新文章采集到自己网站.可挂机,过滤重复贴等,采集文章+翻译伪原创可

狗屁不通文章生成器下载,轻松一点就要编辑出一些所谓的漂亮话,狗屁不通文章生成器app展现的文字乍一看很成文,其实都是写空话,感兴趣的小伙伴就来腾牛网抱走狗屁不通文章生成器手机版。狗屁不通文章生成器手机版是

水淼软件多年专注于技术研发,所有软件皆是原创,系水淼开发的与站长、网络采集、网络发布等相关的系列软件。现有六十多款原创软件和小游戏,致力提供精细分工的各种实用工具、站长SEO软件。水淼软件是更能服务于用户

爬虫软件是什么,爬虫软件有哪些?爬虫软件简单来说就是数据采集工具。像我们平时发布某些信息,如果要想要被百度收录,那就需要百度的蜘蛛抓取到才行。爬虫软件就是数据采集工具的统称,包括了图片采集,商品采集等
 伪原创助手1.0 绿色免费版出版印刷 / 1.8M
伪原创助手1.0 绿色免费版出版印刷 / 1.8M 非常好印(PrintMagic)v5.10.06 官方版出版印刷 / 166.3M水淼万能文章采集器破解版1.22 绿色免费版出版印刷 / 1.1M
非常好印(PrintMagic)v5.10.06 官方版出版印刷 / 166.3M水淼万能文章采集器破解版1.22 绿色免费版出版印刷 / 1.1M 拼版计算助手v1.0 绿色版出版印刷 / 1.4M
拼版计算助手v1.0 绿色版出版印刷 / 1.4M 批量伪原创文章工具v1.0 免费版出版印刷 / 5.5M
批量伪原创文章工具v1.0 免费版出版印刷 / 5.5M i印通自助打印平台v3.9.50520.0 官方版出版印刷 / 120.7M
i印通自助打印平台v3.9.50520.0 官方版出版印刷 / 120.7M
 印通印刷拼版系统v2018 免费版出版印刷 / 1.5M
印通印刷拼版系统v2018 免费版出版印刷 / 1.5M MatterControl(开源3D打印机控制器)v2.20 免费版出版印刷 / 15.7M
MatterControl(开源3D打印机控制器)v2.20 免费版出版印刷 / 15.7M 网钛文章管理系统2.87 免费版出版印刷 / 3.7M
网钛文章管理系统2.87 免费版出版印刷 / 3.7M 印刷神算指1.0 最新版出版印刷 / 36KB伪原创助手1.0 绿色免费版出版印刷 / 1.8MMatterControl(开源3D打印机控制器)v2.20 免费版出版印刷 / 15.7Mi印通自助打印平台v3.9.50520.0 官方版出版印刷 / 120.7M非常好印(PrintMagic)v5.10.06 官方版出版印刷 / 166.3M水淼万能文章采集器破解版1.22 绿色免费版出版印刷 / 1.1M
印刷神算指1.0 最新版出版印刷 / 36KB伪原创助手1.0 绿色免费版出版印刷 / 1.8MMatterControl(开源3D打印机控制器)v2.20 免费版出版印刷 / 15.7Mi印通自助打印平台v3.9.50520.0 官方版出版印刷 / 120.7M非常好印(PrintMagic)v5.10.06 官方版出版印刷 / 166.3M水淼万能文章采集器破解版1.22 绿色免费版出版印刷 / 1.1M 商印通个性定制软件v3.0 安装版出版印刷 / 68.9M拼版计算助手v1.0 绿色版出版印刷 / 1.4M批量伪原创文章工具v1.0 免费版出版印刷 / 5.5M印通印刷拼版系统v2018 免费版出版印刷 / 1.5M
商印通个性定制软件v3.0 安装版出版印刷 / 68.9M拼版计算助手v1.0 绿色版出版印刷 / 1.4M批量伪原创文章工具v1.0 免费版出版印刷 / 5.5M印通印刷拼版系统v2018 免费版出版印刷 / 1.5M 百味小说appv4.03.00 安卓版出版印刷 / 18.1M
百味小说appv4.03.00 安卓版出版印刷 / 18.1M



























 考场自动编排及管理软件v1.0 官方版中文 / 64.1M
考场自动编排及管理软件v1.0 官方版中文 / 64.1M 印Plus分析诊断系统v1.0.1 官方版中文 / 55.3M
印Plus分析诊断系统v1.0.1 官方版中文 / 55.3M 大印客个性印品专家v5.6.3官方版中文 / 19.5M
大印客个性印品专家v5.6.3官方版中文 / 19.5M 航母表格快递单打印软件v5.0.0.2 最新版中文 / 201KB
航母表格快递单打印软件v5.0.0.2 最新版中文 / 201KB 宏达计件工资管理系统v3.0 官方版财务管理
宏达计件工资管理系统v3.0 官方版财务管理 代练通电脑版v19.1.25.1 官方版其他行业
代练通电脑版v19.1.25.1 官方版其他行业 甩手工具箱v5.07 免费版商业贸易
甩手工具箱v5.07 免费版商业贸易 华泰证券网上交易分析系统专业版2v5.53 官方免费版股票证券
华泰证券网上交易分析系统专业版2v5.53 官方免费版股票证券 虎峰人事管理系统v5.0 官方版行政管理
虎峰人事管理系统v5.0 官方版行政管理 招聘之星v4.5.6.5 官方版行政管理
招聘之星v4.5.6.5 官方版行政管理 一键工作室(一键u盘装系统)V4.2UEFI版其他行业
一键工作室(一键u盘装系统)V4.2UEFI版其他行业 AH人事管理系统3.85 免费版行政管理
AH人事管理系统3.85 免费版行政管理 可牛杀毒系统文件修复工具1.1 绿色版其他行业
可牛杀毒系统文件修复工具1.1 绿色版其他行业 鄂公网安备 42011102000260号
鄂公网安备 42011102000260号