- ����



/����/

/����/

/����/

/����/

/����/

/����/

/����/

/����/

/����/

/����/
 ��ѶQQ����v9.7.22.29298 ���°�
��ѶQQ����v9.7.22.29298 ���°� QQ��Ϸ����2023�ٷ�������ʽ��v5.47.57938.0 ���°�
QQ��Ϸ����2023�ٷ�������ʽ��v5.47.57938.0 ���°� QQ���Թܼ�v15.0.22206.230 ������ʽ��
QQ���Թܼ�v15.0.22206.230 ������ʽ�� ����ģ��������v1.0 ��ɫ��
����ģ��������v1.0 ��ɫ�� Ѹ��Ӱ������v6.2.6.622 PC��
Ѹ��Ӱ������v6.2.6.622 PC�� Google Chrome�����v119.0.6045.105 �ٷ����İ�
Google Chrome�����v119.0.6045.105 �ٷ����İ� Ѹ��11��ʽ��ͻ���v12.0.1.2184 �ٷ���
Ѹ��11��ʽ��ͻ���v12.0.1.2184 �ٷ��� ��˼����PC��v7.98.77 �ٷ����°�
��˼����PC��v7.98.77 �ٷ����°� ���������v1.2.9.4001 �ٷ���
���������v1.2.9.4001 �ٷ��� ������PC��ͻ�������v10.8.5.7283 �ٷ�����
������PC��ͻ�������v10.8.5.7283 �ٷ�����bilibili_video_download��һ��dz����õ�bվ��Ƶ�������ع�����������������BiliBili��Ƶ���ܹ�ָ����ҳ����UP����ҳ������Ƶ�ɼ���ʹ�������dz����㣬ֻ��Ҫ������ַ���ɣ�����Ҫ���û��Ͽ������ذɣ�

����ǰ��
����������£���ʹ����������������Web�˵�bilibili�ƺ��������װ��Σ�������Ƶ����ѧϰ���������Python��������bվ��Ƶ����������Ա��Ƶ�������飨�ַ����ҿ����ġ�
�ο���Ƶ��https://www.bilibili.com/video/BV1Fy4y1D7XS
�ڷ���bվ��ҳԴ����Ĺ����з�������Ƶ����Ƶ�Ƿֿ��ģ����غ�һ��ֻ��������һ��ֻ�л��棬����Ȼ�����������ǵ�Ҫ��������ǣ����� ffmpeg ���ǿ��Ŀ�Դ���߰����غ������Ƶ���кϲ�������Ҫ�������飬�ȵ����ذ�װ�����ú� ffmpeg �������������أ���ѹ����ļ����ڵ�bin ���ӵ�����������
Python��ʹ�õ���ģ���У�requests��re��json��subprocess��os
������
��Ƶ��url�Ƚ����ۣ�����ȡ��headersҲ���ң�������Ҫһ��Ҫ��Ϣ��
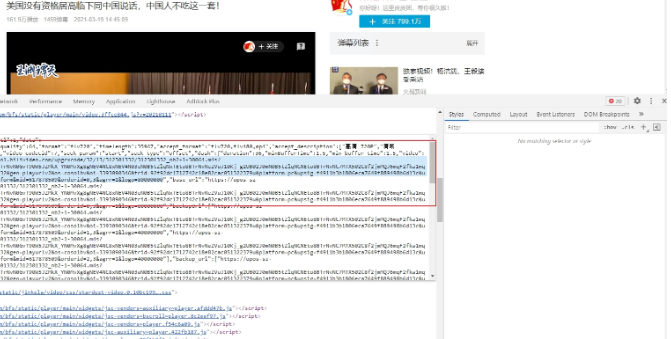
ͨ���������F12���鿴����Ŀ����ҳ���ҵ����ǵ���һĿ�꣬���ӣ�����Ƶ�������ӡ�
һ�����Һ�����head��ĵ��ĸ�script ��ǩ���ƺ���������Ҫ�Ķ�����
�ɷ��ʴ����ӣ�ȴ����403����û��Ȩ���ʴ�վ��
������ô���£��鿴Request Headers ��Ϣ������û��referer��һ����dz��������ݰ��м���referer��Ϣ���ܷ���ʡ�������ֱ����bp�ˣ�
Forward�����ļ�����ҳ�档
���غ���ļ���ȷΪĿ����Ƶ��
��ȡ����
ͨ��requests����Ŀ��վ�㷢���������������header��referer����Ϣ����αװ����������������������������������Ӧ����õ�һ��Response��������Ҫ��ȡ��ҳ�����ݡ�
���Դ��룺
������
��������
�õ������ݿ�����HTML��json�ȸ�ʽ��������ҳ������⡢�������ʽ�Ƚ��н�����
title��Ϣ�ȽϺ��ң�����head�С�
�����������ʽ���������ȡ��
���ƴ��� ���ش��� title = re.findall('<title data-vue-meta="true">(.*?)</title>',html_data)[0].replace("_�������� (�b-�b)�ĥ� �ɱ�~-bilibili",""
����Ƶ����������json�����С�
�����������ʽ���ֵ����б����ġ�����������ȡ��
���Դ��룺
������
��������
ͨ���������ӣ�������Ƶ���ص����ز����档
���Դ��룺
������
�ϲ�����Ƶ
�ѷֿ�����Ƶ����Ƶ���кϲ��������β��������������������Ƶ������Ϊ�ļ���ȥִ��ffmpeg����ᵼ������ִ�����ʱû�ҵ�����������������Ž��ļ�����������Ϊ1.mp3��1.mp4�����������֣�������ɺϲ�����ɾ��֮)
���Դ��룺
������
�ϲ�����Ƶ�������ţ�������ɫ��
���մ���
����
�����exe
��������Ҫ�Ȱ�װPyinstaller��ֱ����cmdʹ��pip����
Ȼ��ffmpeg��py�ļ����õ�ͬһ�ļ����¡�
��Ϊffmpeg��Ҫһ�����ģ���Ҫ�Դ����е���ӦĿ¼��С���ġ��ĺ�Ĵ������£�
�ĺú�cmd�л������Ǹոշ��ļ���Ŀ¼��ִ���������
������-i bilibili.ico�ǶԳ����ͼ��������ã�Ϊ��ѡ�
ִ����ϻᷢ�ֵ�ǰĿ¼���˼����ļ��У���������Ϊdist���ļ��У�����������һ����Ϊbilibili_video_download��exeӦ�ó�����ͼ��Ҳ���������õ�ͼ����������Ҫ��exe�ļ��ƶ�����һ��Ŀ¼����ffmpeg��ͬ��Ŀ¼��
һ�����ش�������ʹ��Bվ�ֻ��ͻ��˴���ע�ᡣ
�����û������Լ��������ӣ�����ij���ϴ�����Ƶ���������ء�Ҳ����ֱ��������
��������Ҫ������Ƶ�����ƣ�ѡ�����������������Դ��
�ġ����Ҫ���ص���Ƶ�����Ҽ����ء�
Ŀǰ����
�������أ�Web|TV����
��ͨ�������أ�Web|TV�� ��TV�ӿڿ������ز���UP������ˮӡ���ݣ���
���P�Զ����ء�
ѡ��ָ����P�������ء�
ѡ��ָ�������Ƚ������ء�
���������Ļ��ת��Ϊsrt��ʽ��
�Զ��ϲ���Ƶ+��Ƶ��+��Ļ����
��ά���¼�˺š�
 cr tubeget��ע�����(YouTube�ռ�������)v0.9.2.3 �ƽ�����ع��� / 36.3M
cr tubeget��ע�����(YouTube�ռ�������)v0.9.2.3 �ƽ�����ع��� / 36.3M Ѹ��7.9��ɫ��v7.9.44.5057 �������ع��� / 29.6M
Ѹ��7.9��ɫ��v7.9.44.5057 �������ع��� / 29.6M Ѹ���ٰ� ����������V1.0.35.366 ���ð����ع��� / 20.1M
Ѹ���ٰ� ����������V1.0.35.366 ���ð����ع��� / 20.1M Ѹ��5��������ذ�v5.8.14.706 ��ɫ�����ع��� / 9.7M
Ѹ��5��������ذ�v5.8.14.706 ��ɫ�����ع��� / 9.7M �����ĵ�������(����)v3.2.14 ��Ѱ����ع��� / 5.9M
�����ĵ�������(����)v3.2.14 ��Ѱ����ع��� / 5.9M
 Ѹ���ٰ�WIN10������(֧����1703��)1.0 ��Ѱ����ع��� / 23M
Ѹ���ٰ�WIN10������(֧����1703��)1.0 ��Ѱ����ع��� / 23M Ѹ���ٰ�1.0��ɫ�����1.0.35.366 ȥ�������ع��� / 21M
Ѹ���ٰ�1.0��ɫ�����1.0.35.366 ȥ�������ع��� / 21M ��צ��ɼ�����ɫ��v7.4.4 ����ƽ�����ع��� / 55.8M
��צ��ɼ�����ɫ��v7.4.4 ����ƽ�����ع��� / 55.8M Ѹ��7ȥ��滳�ɰ���Ѱ����ع��� / 20M
Ѹ��7ȥ��滳�ɰ���Ѱ����ع��� / 20M Ѹ��5.8ȥ��治�����ȶ������ع��� / 9.1Mcr tubeget��ע�����(YouTube�ռ�������)v0.9.2.3 �ƽ�����ع��� / 36.3MѸ��7.9��ɫ��v7.9.44.5057 �������ع��� / 29.6MѸ���ٰ� ����������V1.0.35.366 ���ð����ع��� / 20.1M
Ѹ��5.8ȥ��治�����ȶ������ع��� / 9.1Mcr tubeget��ע�����(YouTube�ռ�������)v0.9.2.3 �ƽ�����ع��� / 36.3MѸ��7.9��ɫ��v7.9.44.5057 �������ع��� / 29.6MѸ���ٰ� ����������V1.0.35.366 ���ð����ع��� / 20.1M P2psearcher������������ȥ���ư�v3.5 ��ذ����ع��� / 2.1M
P2psearcher������������ȥ���ư�v3.5 ��ذ����ع��� / 2.1M P2pSearcher�������������ļ���ɫ��ǿ��v8.8 ���°����ع��� / 1.8MѸ��5��������ذ�v5.8.14.706 ��ɫ�����ع��� / 9.7M�����ĵ�������(����)v3.2.14 ��Ѱ����ع��� / 5.9MѸ���ٰ�1.0��ɫ�����1.0.35.366 ȥ�������ع��� / 21MѸ���ٰ�WIN10������(֧����1703��)1.0 ��Ѱ����ع��� / 23M
P2pSearcher�������������ļ���ɫ��ǿ��v8.8 ���°����ع��� / 1.8MѸ��5��������ذ�v5.8.14.706 ��ɫ�����ع��� / 9.7M�����ĵ�������(����)v3.2.14 ��Ѱ����ع��� / 5.9MѸ���ٰ�1.0��ɫ�����1.0.35.366 ȥ�������ع��� / 21MѸ���ٰ�WIN10������(֧����1703��)1.0 ��Ѱ����ع��� / 23M Ѹ��5.8�������ȶ���(֧��win10)v5.8.14.706 ��ɫ�����ع��� / 9.30GGoogle Chrome�����v119.0.6045.105 �ٷ����İ��������Ѹ��11��ʽ��ͻ���v12.0.1.2184 �ٷ������ع���
Ѹ��5.8�������ȶ���(֧��win10)v5.8.14.706 ��ɫ�����ع��� / 9.30GGoogle Chrome�����v119.0.6045.105 �ٷ����İ��������Ѹ��11��ʽ��ͻ���v12.0.1.2184 �ٷ������ع��� teamviewerv15.44.5.0 �ٷ���Զ�̿���
teamviewerv15.44.5.0 �ٷ���Զ�̿��� 360��ȫ���������v14.1.1116.0 �ٷ����°��������
360��ȫ���������v14.1.1116.0 �ٷ����°�������� Foxmail����v7.2.25.228 ���°������ʼ�
Foxmail����v7.2.25.228 ���°������ʼ� ��Ѷ�����̵���v5.2.1307 pc�ͻ�������洢
��Ѷ�����̵���v5.2.1307 pc�ͻ�������洢 360���������PC������v13.5.2042.0 �ٷ�32λ���������
360���������PC������v13.5.2042.0 �ٷ�32λ��������� ���տ�Զ�̿�������v13.2.0.55335 �ٷ���Զ�̿���
���տ�Զ�̿�������v13.2.0.55335 �ٷ���Զ�̿��� xshell7��Ѱ�v7.0.99.0 ��ɫ����������
xshell7��Ѱ�v7.0.99.0 ��ɫ����������







 ���ؾ���(BitSpirit)v3.6.0.550 �ٷ������� / 2.2M
���ؾ���(BitSpirit)v3.6.0.550 �ٷ������� / 2.2M ˶��flv��Ƶ������v0.4.8.10 ��ʽ������ / 7.4M
˶��flv��Ƶ������v0.4.8.10 ��ʽ������ / 7.4M Ѹ��u����v3.2.0.472 ���°����� / 27.1M
Ѹ��u����v3.2.0.472 ���°����� / 27.1M �����ֽԤ�����ع���1.0 ��ʽ������ / 749KB
�����ֽԤ�����ع���1.0 ��ʽ������ / 749KB ���������� 42011102000260��
���������� 42011102000260��